运维不是一门手艺,是一门科学
一、被忽视了十年的真相
过去十年,运维行业最用力的事之一,是“更快地发现问题”。于是采集粒度越来越细,监控指标越来越多,通知渠道越来越丰富。这背后的逻辑很简单:信息越充分,决策就越准确。
但事实真的如此吗?——当 200 个监控指标同时报警,问题从来不是“缺少信息”,而是信息过载本身。
2024 年某头部券商的真实场景:一笔交易延迟抖动,触发了从网关到数据库共 217 条告警,覆盖 4 个技术栈、12 个微服务。值班工程师要在这一片告警洪流中,拼出一条因果链——而人类大脑能同时处理的信息通道,只有 4±1 个。
这意味着,他不是在排查问题,而是在噪声里找一根针。
故障定位,整整耗去 2 小时 17 分钟。
在这段时间里,交易系统始终卡在一种“明知道有问题但不知道问题在哪”的半瘫痪状态。
运维团队把这叫“故障恢复”。但更准确的描述是:一场人力对抗复杂性的拉锯战——而人,从一开始就不可能赢。
二、不是升级工具,是更换地基
面对这个困境,本能的反应是:让工具更智能。
但这是在旧逻辑里打补丁。
真正的变化,不是把旧工具升级成新工具,而是更新思考问题的方式。就像化学不是“更好的炼金术”——它不是把炼金配方优化了一遍,而是用元素周期表和反应方程,重建了理解物质的整套框架。
运维正在经历同样的事。
过去三十年,它本质上是一门经验驱动的手艺——老师傅靠“见过”积累判断力,靠“直觉”定位问题。
但今天的系统复杂度,已经超出了任何一个人脑的认知带宽。
这不是靠“更多经验”能解决的——需要从“人脑处理信息”转向“机器理解系统”,从“经验匹配”转向“数据推理”,从手艺,到科学。
这正是云智慧在做的事——搭建这门“科学”的底层设施。让系统自己理解自己。
三、同一场洪流,不同的结局
回到那家券商。同一笔交易延迟,同样的 217 条告警——但这次,云智慧的AI SRE 智能体Castrel AI 接管了整个过程。
217 条告警涌入系统。但它们没有涌入值班工程师的手机。
大模型降噪引擎基于时序和拓扑关联,将 217 条告警压缩为一条因果链。工程师收到的推送只有一条:「交易服务延迟异常,疑似根因:xx 服务代码层异常,关联影响:20个上下游服务」。
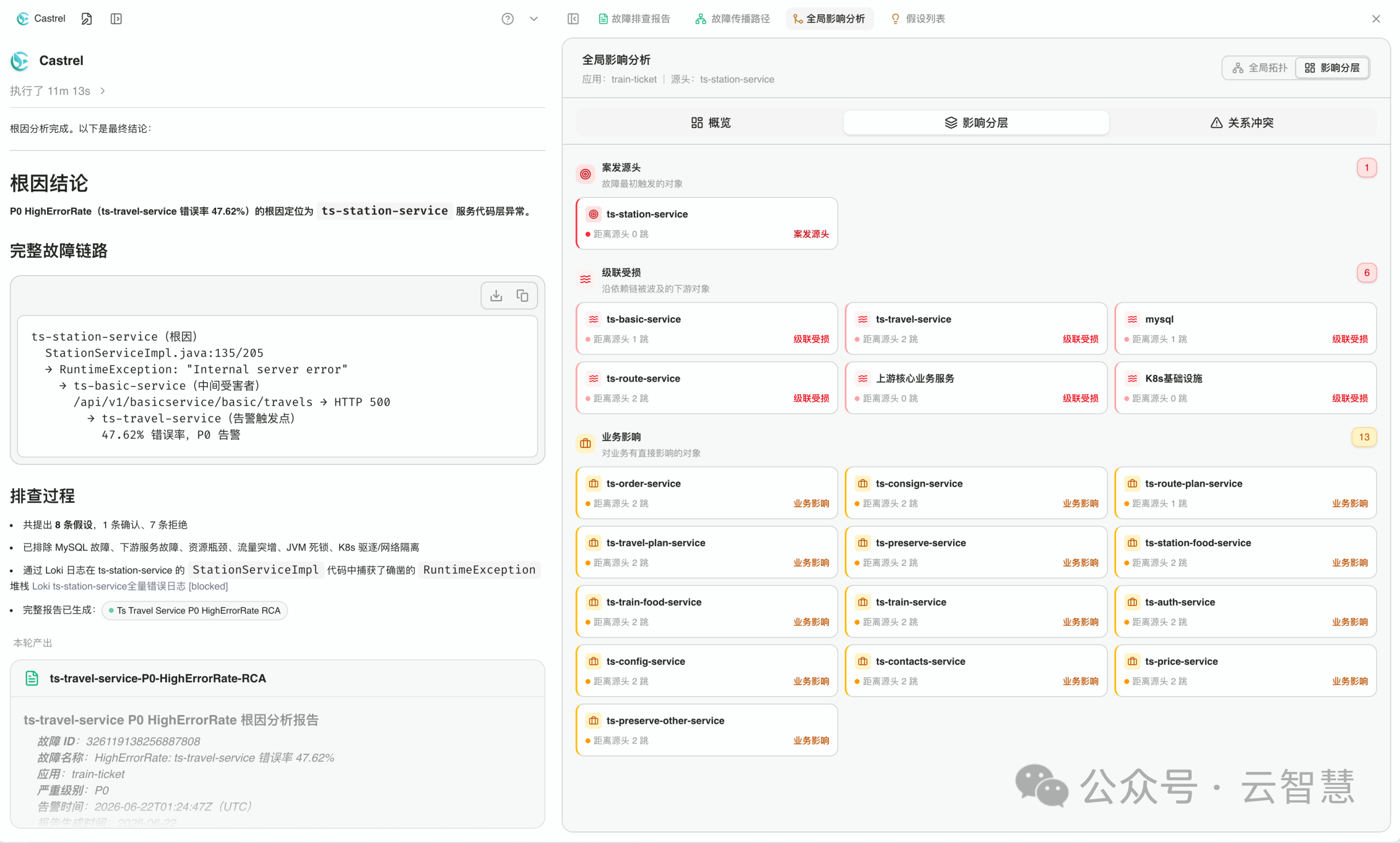
告警压缩后,Castrel AI 接管推理。传统 CMDB 在这种时刻毫无用处——它只记录状态,不记录关系,而故障从来不沿“状态”传播,只沿“关系”传播。
云智慧将 CMDB 重构为动态知识图谱:全栈资源自动发现,依赖关系实时更新。Castrel AI 在这张图谱上推理路径,而不是在告警里搜索答案。
5 分钟,根因定位完成。
而上一次,同样的场景,答案是:2 小时 17 分钟。
随即,自动修复启动:扩容连接池、隔离故障节点、流量切换至备用实例。从告警触发到业务恢复,全程 36 分钟。MTTR从小时级降到分钟级。
对日交易额过亿的券商而言,省下的不仅是时间——是本该发生的交易失败、客户流失和合规风险。不是减少了,是没有发生。
当 MTTR 从小时级降到分钟级,“故障”这个词本身被重新定义了——从“需要人介入的紧急事件”,变成“系统自愈的常规波动”。
四、在故障发生之前理解它
故障来了,5分钟定位,36分钟恢复——已经足够快了。但如果故障根本不需要发生呢?
大部分生产事故在爆发前,都有至少一个先行信号——一次不规范的变更、一段持续攀升的资源占用、一条被忽略的基线偏移。这些信号不是不存在,而是淹没在海量指标里,没有人即时发现。
某大型银行的真实案例:云智慧智能巡检系统在一次全栈扫描中,发现核心交易系统的数据库连接数在过去 72 小时内持续攀升——尚未触发任何阈值告警,单独看完全在“正常范围”内。
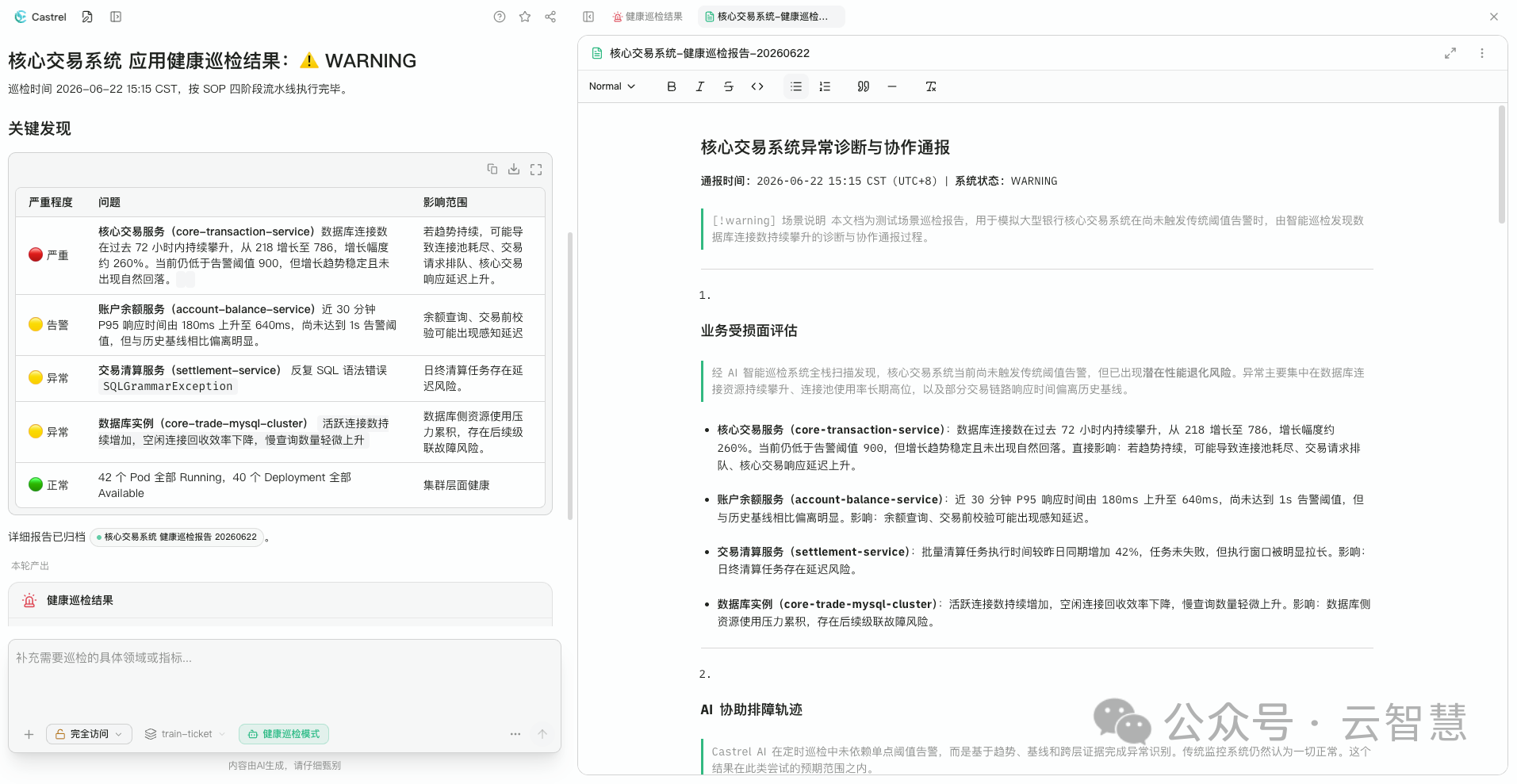
但系统将这个指标与变更记录、业务周期、历史基线深度关联后,识别出异常模式:一周前的版本发布引入了一个未释放连接的代码缺陷,连接数以每天 3% 的速度泄漏。按这个速度,5 天后连接池将耗尽——届时触发的,将是那家券商经历过的同一种 P1 故障。
故障发生前 5 天,预警发出。修复建议自动生成,工单自动创建并分派至对应团队。从发现到闭环,全程无需人工发起。
这不是“更快地发现问题”。这是问题根本没有机会发生。
五、当物理世界也开始被理解
前面讲的,都是软件世界的事。但真正的复杂系统,也存在于物理空间。
传统数据中心巡检的经典画面:工程师拿着巡检表走过一排排机柜,听风扇声音、摸设备温度、看指示灯状态。一座数据中心有8000个机柜。几乎没有人能在一次巡检中记住每一台的状态,更没有人能凭直觉判断哪台设备的温度异常可能引发连锁故障。
云智慧的智能巡检机器人Cloudwise X1 改变了这个画面。
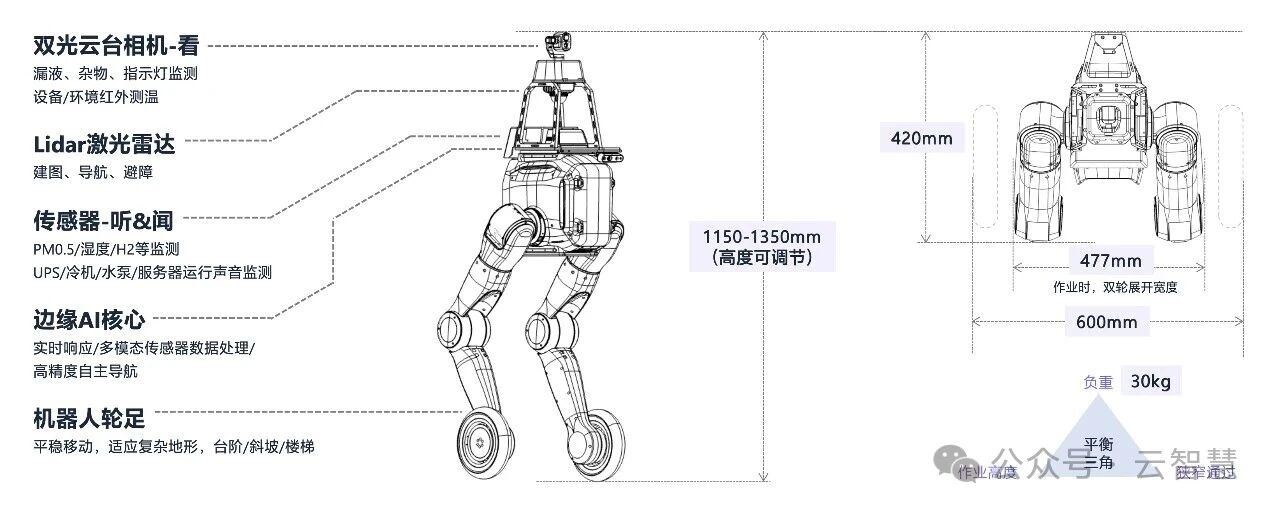
当某台设备温度异常时,系统不是孤立地报一条告警,而是追溯热力路径、关联 IT 负载,判断它是一个孤立的热点还是一场连锁故障的起点——然后自动计算调整方案并执行。
当物理世界的状态可以被实时感知、数字建模和智能推理,运维的对象就不再只是软件系统,而是整个数字物理世界。
云智慧将同样的逻辑——感知、理解、干预——运用到电力行业,通过 AI Power完成电力系统的可靠性管理。
范式一旦迁移,边界自然扩展。
六、一个还没被回答的问题
当 AI 可以5分钟定位根因、5天前预判故障、7×24小时巡检物理世界,一个新的问题浮现了——运维工程师的核心竞争力是什么?
不是排查速度——AI 快三个数量级。不是经验积累——AI 见过更多的故障模式。不是流程执行——自动化已经接管了闭环。
当AI把“响应”这件事做到极致,人需要把战场前移:更早地设计——在故障被写入系统之前就把它识别出来,在架构还停留在图纸上时就把它排除掉。
这不是“释放人去做更有价值的事”这种“陈词滥调”。这是一种职业身份的根本重构:从系统的消防员,到系统的设计者。
我们正在经历的,不是工具的升级,是认知地基的更换。
而这,才是这场迁移中最难的部分。
联系方式:400-666-1332